前言
这篇文章主要是帮大家梳理下Stable diffusion里面的各种模型,模型在Stable diffusion中占据着至关重要的地位,不仅决定了出图的风格,也决定了出图质量的好坏。
但在第一次接触SD的时候,我就被里面的模型搞到头大,不仅有多种模型后缀,模型之间也有很多种类型,如果是新手小白的话,在这一步就很容易被搞晕。而在本期文章,技术巫帮你系统梳理了SD的模型,相信不管是对于小白还是老手,都会有一定帮助!
一、从模型后缀说起
为了更好地理解模型,让我们先从模型的后缀说起。
在Stable diffusion中,有两种比较常见的模型后缀,分别是 .ckpt 和 .safetensors 。
.ckpt 的全称是 checkpoint,中文翻译就是检查点,这是 TensorFlow中用于保存模型参数的格式,通常与 .meta 文件一起使用,以便恢复训练过程。
简单理解的话,.ckpt模型就好比我们打游戏时,每通过一关时对这一关的一个“存档”,因为你在训练模型时也是如此,没办法保证能一次就训练成功,中途是有可能因为各种因素失败的,所以可能在训练到20%时就存一次档,训练到40%时又存一次档,这也是为什么它叫 checkpoint 的一个原因。
在提到.ckpt 模型时,我想顺便补充下.pt 模型,前面提到,.ckpt 是TensorFlow 用于保存模型参数的格式,而 .pt 则是 PyTorch保存模型参数的格式。TensorFlow 和 PyTorch都是比较出名的深度学习框架,只不过一个是Google发布的,另外一个是Facebook发布的。
PyTorch 保存模型的格式除了.pt 之外,还有 .pth 和.pkl。.pt 和 .pth 之间并没有本质的差别,而.pkl 只是多了一步用Python的 pickle 模块进行序列化。
讲完了 .ckpt 模型,那么就该说说 .safetensors 模型了。
之所以有 .safetensors 模型,是因为 .ckpt 为了让我们能够从之前训练的状态恢复训练,好比从50%这个点位重新开始训练,从而保存了比较多的训练信息,比如模型的权重、优化器的状态还有一些Python代码。
这种做法有两个问题,一是可能包含恶意代码,因此不建议从未知或不信任的来源下载并加载.ckpt 模型文件;二是模型的体积较大,一般真人版的单个模型的大小在7GB左右,动漫版的在2-5GB之间。
而 .safetensors 模型则是 huggingface 推出的新的模型存储格式,专门为Stable Diffusion模型设计。这种格式的文件只保存模型的权重,而不包含优化器状态或其他信息,这也就意味着它通常用于模型的最终版本,当我们只关心模型的性能,而不需要了解训练过程中的详细信息时,这种格式便是一个很好的选择。
由于 .safetensors 只保存模型的权重,没有代码,所以会更安全;另外由于保存的信息更少,所以它的体积也比 .ckpt 小,加载也更快,所以目前是比较推荐使用 .safetensors 的模型文件。
总的来说,如果你想在某个SD模型上进行微调,那还是得用 .ckpt 模型;但如果你只关心出图结果,那么使用 .safetensors 模型会更好!
二、从模型分类讲起
在Stable diffusion中,模型主要分为五大类,分别是Stable diffusion模型、VAE模型、Lora模型、Embedding模型以及Hypernetwork模型。
2.1 Stable diffusion大模型
这类模型俗称“底模”,对应下面这个位置。
这类模型代表了Stable diffusion的一个知识库,比如说我们训练大模型用的全是二次元的图片,那么它最终生成的图片效果也会趋于二次元;而如果训练的时候用的是真人图片,则最终出图效果则趋于真人。
由于这类模型包含的素材非常多,训练的时间也非常长,所以体积也比较大,一般在2GB以上,后缀的话就是上面提到的 .ckpt 和 .safetensors
2.2 VAE模型
VAE全称Variational autoenconder,中文叫变分自编码器,这种模型可以简单理解为起到一个滤镜的效果。在生成图片的过程中,主要影响的是图片的颜色效果。
一般来讲,在生成图片时,如果没有外挂VAE模型,生成的图片整体颜色会比较暗淡;而外挂了VAE模型的图片整体颜色会比较明亮。
注:左边是没有使用VAE生成的图片,右边是使用VAE生成的图片
不过需要注意的是,有一些大模型在训练的时候就已经嵌入了VAE的效果,所以即使没有使用VAE效果,出图的效果也不会那么暗淡。
另外,有时候使用VAE反倒会出现一个不好的效果,比如在最后一刻变成一张蓝色废图,这时候就需要把外挂VAE改成自动(Automatic)即可
注:像这种即为蓝色废图
2.3 Lora模型
Lora模型想必大家都经常看到了,LoRA的英文全称为Low-Rank Adaptation of Large Language Models,直译为“大语言模型的低阶适应”。这是一项由微软研究人员提出的大语言模型微调技术,简单来说,它的作用是让这些庞大的模型变得更加灵活和高效,能够在特定任务上进行优化(比如对样式进行一些修改),而不需要从头开始训练整个模型。
比如像下面这个Lora模型,就是在大模型的基础上增加一些森林水母发光的效果(就是我们不必为了增加这个效果,重新训练我们的大模型,因为训练大模型花费时间很长,通过Lora就可以提高效率)
需要注意的是,Lora模型并不能单独使用,它必须与前面的大模型一起使用!
另外,由于Lora训练的图片较少,比如上面的Lora就是用100+图片训练的,所以它的体积一般不会很大,一般在几十到几百MB之间,这样大大节省了磁盘的占用量。
最后,有些Lora模型启用是需要触发词的(也就是在提示词那里加上这个触发词),比如上面的Lora触发词就是 jellyfishforest
2.4 Embedding模型
Embedding模型也称为textual inversion,即文本反转。在Stable Diffusion中,Embedding模型使用了嵌入技术以将一系列输入提示词打包成一个向量,从而提高图片生成的稳定性和准确性。
简单来说,如果我们要通过SD生成火影里面的鸣人形象,我们需要好几个提示词来进行描述,比如什么外形,穿什么颜色的衣服,而Embedding就是将这一系列提示词打包成为一个新的提示词,假设叫鸣人。
这样后续我们只要引入这个 Embedding模型,然后输入鸣人提示词,就会生成我们想要的鸣人形象,提高了写提示词的效率!
由于Embedding模型只是将提示词整合了,所以它的体积非常小,一般在几十到几百KB之间。
举个例子,比如像这个 Embedding 模型,它描绘了一位叫Caroline Dare的美女
当我们输入触发词时,就会生成类似的美女

虽然生成的图片不是一模一样,因为这跟你使用的底模有关,但是比较明显的特征是一致的。

2.5 Hypernetwork模型
Hypernetwork可以翻译为“超网络”,它是一种基于神经网络的模型,可以快速生成其他神经网络的参数,常应用于Novel AI的Stable Diffusion模型中。
Hypernetwork可以用来对模型进行微调,比如在Stable Diffusion这样的图像生成模型中,通过插入一个小型的超网络来修改输出风格,而不改变原始模型的核心结构
这个模型的作用其实和Lora模型功能有点重叠,所以在实际使用中,我个人用得比较少。
三、模型的剪枝
大家在下载模型的时候,可能还会看到两个版本,一个版本带 pruned,另外一个版本是带 pruned-emaonly。
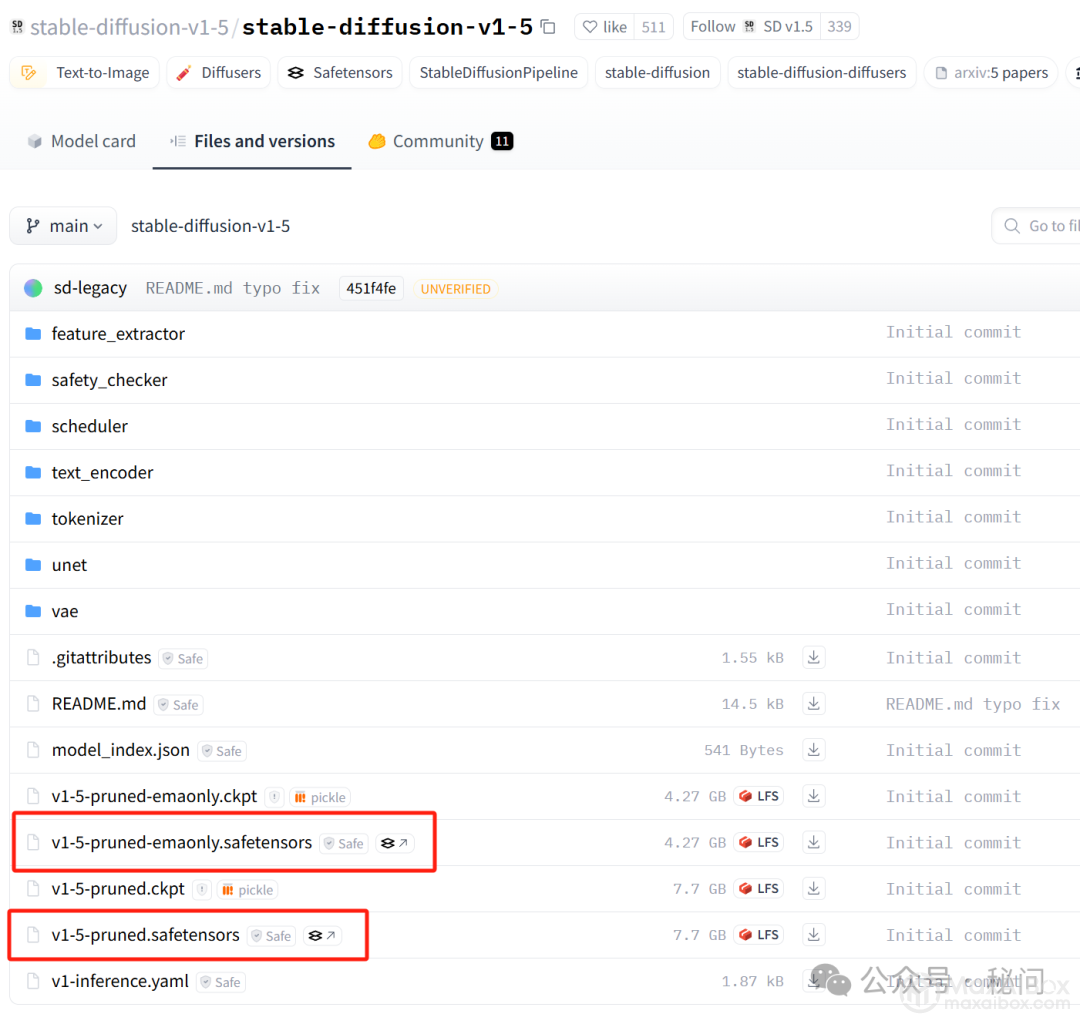
这是因为大模型在训练的时候会保存两组不同类型的权重:第一组取的是最后一次的权重,也就是只带 pruned 的模型。
在深度学习模型训练的过程中,模型的参数(或称为“权重”)会在每一次迭代(或训练步)中根据损失函数(loss function)对数据的拟合情况进行调整。当训练结束时,模型所拥有的权重就是经过所有训练样本反复教导后的最终状态。这部分权重代表了模型在训练数据上学习到的知识,没有经过额外的平滑处理,直接反映了最后一次更新的结果
而第二组则是最近几次迭代的权重进行加权平均,加权平均即EMA(Exponential Moving Average),使用加权平均主要是减少短期波动的影响,这样得到的模型泛化性更好,也更稳定,也就是带 pruned-emaonly 的模型
由于带 pruned-emaonly 的模型体积更小,所以占用的显存(VRAM)也更少,适合用于直接出图;带 pruned 的模型体积更大,占用的显存也更多,更适合对其进行微调,如下图:
四、常用模型介绍
Stable diffusion的模型除了上述的分类之外,从用途上看,还分为官方模型、二次元模型(动漫)、真实系模型和2.5D模型四大类。
4.1 官方模型
官方模型有 1.X 和 2.X 两个大版本,目前在 1.X 中官方发布的有四个版本,分别是v1-1、v1-2、v1-3、v1-4
但是 1.X 其实还有一个 v1-5 的版本,这个版本不是 CompVis 发布的,而是Runwayml发布的,而Runway就是那个文生视频比较出名的公司,据说这个版本在文本到图像生成任务上表现尤为出色,能够生成更符合用户需求的图像(不过我没试过)。
2.X 目前一共有两个版本,分别是2-0和2-1,但变成了stabilityai 发布了
4.2 二次元模型
二次元模型比较出名的当属Anything系列(万象熔炉),像秋叶整合包默认就带了anything-v5-PrtRE 模型。
Anything系列型号目前有四个基本版本V1,V2.1,V3和V5,Prt是V5的特殊装饰版本,是比较推荐的版本。
Anything系列除了生成二次元外,其实对于肖像、风景、动物等也具有较强的适应性和泛用性,是一个比较通用的模型
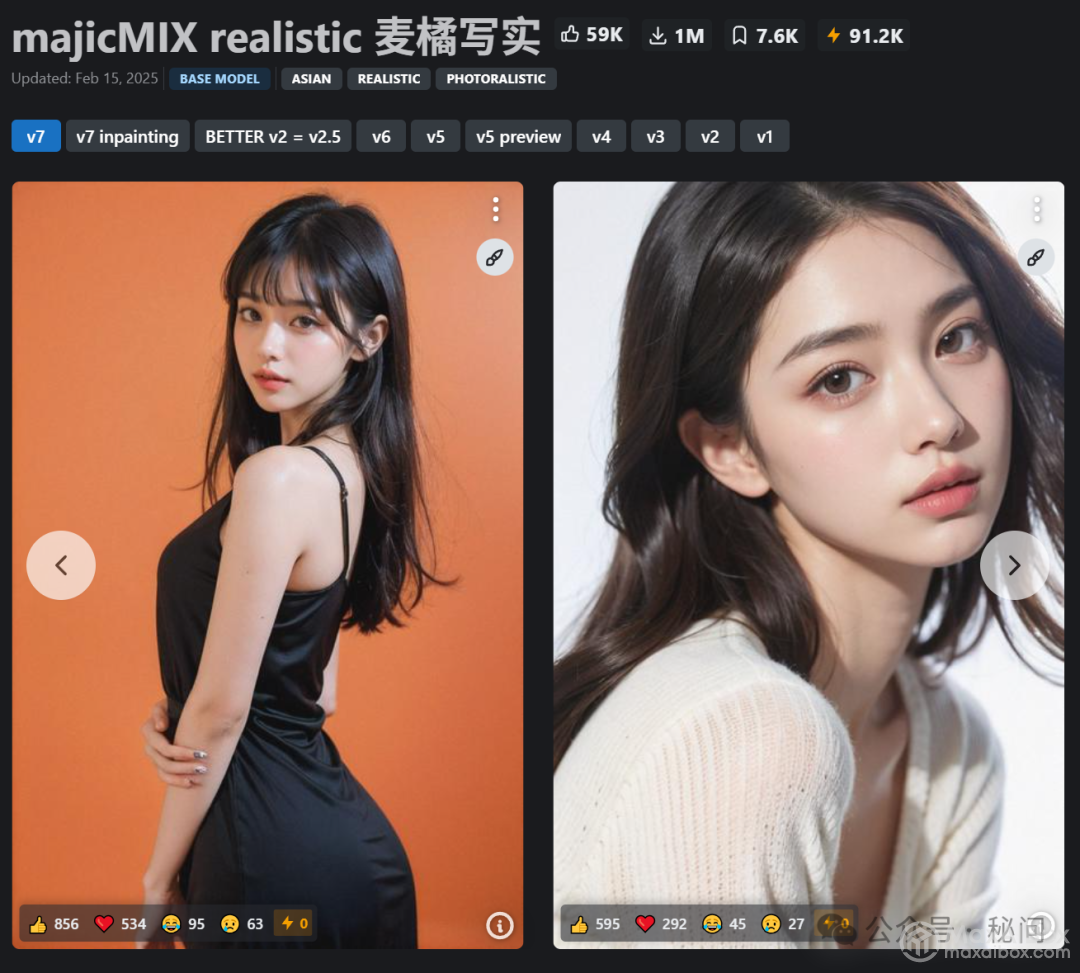
4.3 真实系模型
真实系比较出名的模型有majicMIX realistic等,这是C站上放出的一些图片,可以看到确实非常逼真了
4.4 2.5D模型
2.5D是半3D的意思,简单来说,2D是平面图形,如图片等没有厚度和轮廓的图形。而3D是具有厚度、可以从各个角度观看的立体图形,例如通过3D打印出来的实物模型。2.5D位于2D和3D之间,它加入了部分3D元素但不完全是3D
比较出名的2.5D模型有GuoFeng3等,这是它的一些效果图
5. SDXL模型
与之前的SD1.5大模型不同,SDXL在架构上采用了“两步走”的生图方式:
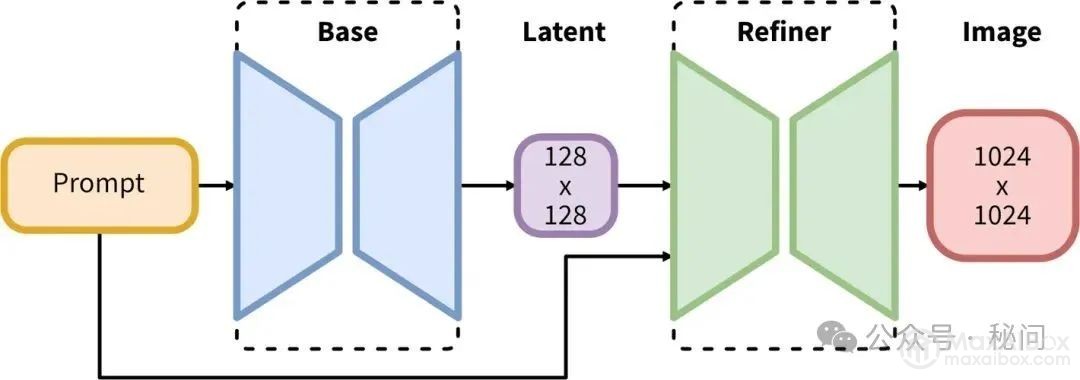
以往SD1.5大模型,生成步骤为 Prompt → Base → Image,比较简单直接;而这次的SDXL大模型则是在中间加了一步 Refiner。Refiner的作用是什么呢?简单来说就是能够自动对图像进行优化,提高图像质量和清晰度,减少人工干预的需要。
简单来说,SDXL这种设计就是先用基础模型(Base)生成一张看起来差不多的图片,然后再使用一个图像精修模型(Refiner)进行打磨,从而让图片生成的质量更高。而在没有这个之前,我们往往需要通过其他手段,如高清修复或面部修复来进行调优。
除了有出图质量更高这个优势,SDXL还有以下优点:
支持更高像素的图片(1024 x 1024)
对提示词的理解能力更好,比较简短的提示词也能达到不错的效果
相比SD1.5模型,在断肢断手多指的情况上有所改善
风格更为多样化

当然,每件事物不可能是完美的,所以SDXL也有一些局限性:
1、低像素出图质量不高
由于SDXL都是用1024×1024的图片训练的,这既导致它在这个像素级别上生成的质量比较高。但同时也导致了它在低像素级别(如512×512)生成的质量反而比较低,甚至不如SD1.5等模型。
2、与旧Lora不兼容
过去一些适用于SD1.5, 2.x 的Lora和ControlNet模型,大概率无法使用,得重新找一些带有SDXL的模型
3、对GPU显存的要求更高
4、出图时间也变久了
模型的下载
这次模型的下载有点不同,因为我们需要下载三个模型,分别是:sd_xl_base_1.0.safetensors、sd_xl_refiner_1.0.safetensors 和 sdxl_vae.safetensors。
三个模型的地址分别是:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
https://huggingface.co/stabilityai/sdxl-vae/tree/main
6. SD3模型
相比SD之前的版本,SD3有比较大的改进。首先,SD3是一个基于Rectified Flow的生成模型;其次,SD3引入了T5-XXL来作为text encoder来提升模型的文本理解能力;最后,SD3采用了一个多模态的DiT架构,并且将模型参数量扩展为8B。从目前给出的例子和评测上,SD3在文字渲染和对文本提示词的遵循上,已经达到甚至超过目前STOA的文生图模型如DALL·E 3、Midjourney v6和Ideogram v1。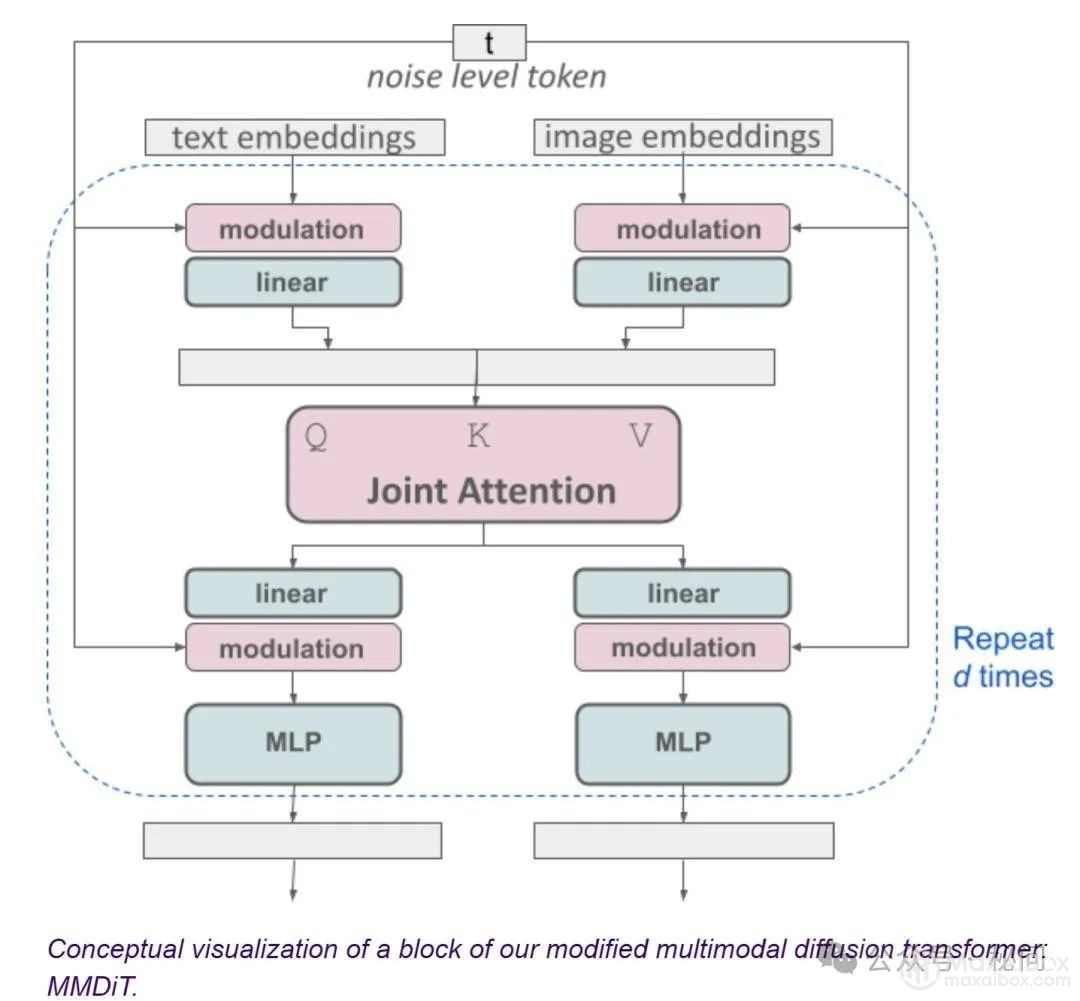
模型结合了三种不同的文本嵌入器——两个CLIP模型和一个T5,以编码文本表示,并使用改进的自动编码模型对图像token进行编码。其核心采用了与Sora相同的DiT技术。
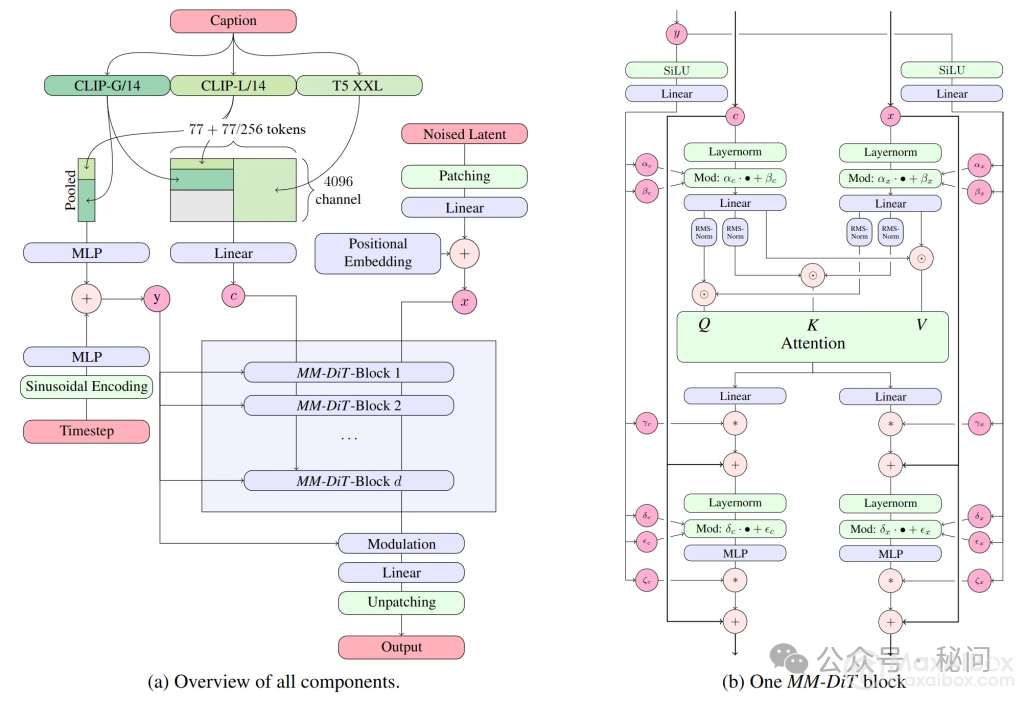
此次开放的模型准确来说是 Stable Diffusion 3 Medium,包含 20 亿参数,具有体积小、适合在消费级 PC 和笔记本电脑上运行的优点,所以普通人也可以将其部署到自己的电脑上使用。SD3 Medium 的优点包括:
① 图像质量整体提升,能生成照片般细节逼真、色彩鲜艳、光照自然的图像;能灵活适应多种风格,无需微调,仅通过提示词就能生成动漫、厚涂等风格化图像;具有 16 通道的 VAE,可以更好地表现手部以及面部细节。
② 能够理解复杂的自然语言提示,如空间推理、构图元素、姿势动作、风格描述等。对于「第一瓶是蓝色的,标签是“1.5”,第二瓶是红色的,标签是“SDXL”,第三瓶是绿色的,标签是“SD3”」这样复杂的内容,SD3 依旧能准确生成,而且文本效果比 Midjourney 还要准确。
③ 通过 Diffusion Transformer 架构,SD3 Medium 在英文文本拼写、字距等方面更加正确合理。Stability AI 在发布 SD3 官方公告时,头图就是直接用 SD3 生成的,效果非常惊艳。

Prompt: 木桌上放着三个透明玻璃瓶。左边的是红色液体,数字是 1。中间的是蓝色液体,数字是 2。右边的是绿色液体和数字 3。
这个案例展示了SD3不仅能生成静态图像,还能模拟现实世界的物理特性,如透明度和光影效果,进一步丰富了AI艺术的表现力。
另外此次 SD3 Medium 模型的授权范围是开放的非商业许可证,也就是说没有官方许可的情况下,模型不得用于商业用途,这点是需要大家注意的。
虽然 SD3 在图像质量、细节、对提示词的理解、文本内容生成能力上有了明显提升,但是也存在一些不足,比如在生成手部的时候依旧会出现错误,以及在生成 “lying(躺)” 这个姿势时,人物会出现严重的崩坏。有人推测是因为 SD3 对内容安全有严格审查,导致相关内容受到影响。
7. SD3.5模型
Stable Diffusion 3.5(简称SD 3.5)是Stability AI 推出的最新图像生成模型,是3.0版本的升级版。这次的更新主要提升了图像质量,还优化了运行速度,尤其是在本地部署和硬件要求上更具弹性。最让人眼前一亮的功能,就是可以生成百万像素级别的高分辨率图片,直接输出专业级别的图像,不需要再二次放大。这意味着,即便你只是日常使用,也能获得相当高质量的成品。

版本介绍:Large、Large Turbo 和 Medium 版本的区别:
SD 3.5 一共有三个主要版本:Large、Large Turbo 和即将发布的 Medium。这些版本的不同之处,简单来说就是“大小”和“速度”的平衡。
Large 版本
• 参数量:80亿。
• 分辨率:支持生成1MP(百万像素)及以上的高清图像。
• 适用场景:适合需要精细、高分辨率图像的用户,比如专业设计师或者有高级绘画需求的人。
Large Turbo 版本
• 参数量:跟Large差不多,但做了精简。
• 分辨率:几乎和Large相同,但生成速度更快。
• 适用场景:对生成速度要求高的用户,可以在几乎不损失太多质量的前提下,快速出图。
Medium 版本(10月29日发布)
• 参数量:25亿。
• 分辨率:支持生成0.25MP到2MP的图像。
• 适用场景:适合电脑配置较低的用户。这个版本在速度上会有优势,适合那些不追求极致画质的场景。
对比 Flux 和 MidJourney:谁更强?
那么,SD 3.5 和 Flux 以及 MidJourney 比起来怎么样呢?总的来说,它们的性能和功能都处在一个水平线,但各有侧重。
Flux 大模型
Flux 更擅长创意发散,生成的图像在创意性和风格多样性上有着不错的表现,尤其是在一些实验性风格或者复杂的艺术风格上,表现得更加出色。如果你是追求极致艺术创作的用户,Flux 会让你更满意。
MidJourney
MidJourney 在艺术性和细节处理上一直表现得很好。它可以生成非常精美的艺术画作,尤其是对一些细节的把控更为细腻,生成的画面有着更强的艺术感。如果你是想要生成一些氛围感强烈的图像,MidJourney 是不错的选择。
SD 3.5
SD 3.5 在质量和速度上都达到了不错的水准,特别是它的商用友好政策让它对一些小型创作者来说很有吸引力。不过,在创意性和细节处理上,它并没有超越 Flux 或 MidJourney,只是达到了同样的水平。对于大多数用户来说,这三者的差异并不影响实际使用体验,完全看你个人的偏好和需求。
8. SD 3.5对比Flux
照片写实主题
1. 专业摄影/电影效果人像

这一轮我得承认SD3.5远远胜过Flux dev。虽然如果要抠字眼的话,Flux确实对我提示词中写到的“front view”“golden hour”和“hair made of branches”有更好的呈现,但是SD3.5的色彩和打光明显要比Flux“漂亮”很多,甚至可以说是接近Midjourney V6.1的水平。这种审美水平在开源模型里其实是非常难得的(我迄今仍然在traumatized by AuraFlow……笑死),尤其是我后来发现aesthetic其实是一种很抽象的东西,有人也专门用MJ做的图去微调过Flux,但是我看了下效果离真正的MJ生成图还是差非常远。(顺便一说,我不知道SD官方Replicate页面用的是什么黑魔法,但是我的这个提示词只有在官方付费渠道才生成得出来“树枝做的身体”,本地运行的就是死活做不出来,再怎么整CFG或者Dynamic Thresholding都没卵用)

……这轮我能说还是SD3.5胜吗?虽然胜得不多,但在我心里还是胜。首先,我选择这个提示词就是因为过去的SD和Flux对于“water caustics”究竟是什么鬼东西完全没有数,只有MJ和Ideogram做得出来。说实话,SD3.5的water caustics虽然也算不上好,但是我感觉它的理解还是相对来讲好一些,而且Flux做得感觉人物根本就不在水下,就好像是那种,普通环境里加上了一个水池和打光一样,看起来很假。除此之外Flux的锁骨阴影实在是……当然这个后来被人微调了就解决了,但我们现在都是比较官方基模嘛。

啊……这个主题我觉得只能说打个平手吧,Flux对于手的结构的呈现还是明显更好(它这一点可以说是非常出名了hhhhh),但是细看的话会觉得Flux的手指有点太统一了,就是中间三根手指好像都长得一模一样。SD3.5的手指在皮肤细节上看起来更自然,但是红得有点过头了(等等好像Flux的手也很红,笑死),而且右手的手背莫名其妙陷下去一块儿,左手虎口那里的皮肤明显就不对,当然SD这张图最大的问题还是在钢琴hhhhh右边怎么就没了!不过还是得说真的很佩服Flux做钢琴的能力,从左到右虽然黑键有一些问题,白键之间的距离和宽度等等都是极其精准地相等,这个还是很厉害的。
2. 随手拍/业余风格人像

这轮SD3.5输得太彻底了,完全没有任何还手的余地。提示词里大部分的要求全都没做到,身材也不slim,也没坐在床的前边缘,也没用手捋头发,室内光线也不够暗,台灯也不是唯一的光源,看起来也不像普通人随便拍的。SD3.5这轮出的图完全只能说是SDXL的水平,腿还陷在床里了(标志性SDXL,笑死),总之非常糟糕。

啊这……SD3.5还是输得很惨。主要是手指太cursed了……但是用这个提示词Flux也没有逃过浅景深的命运,然而整体来说SD感觉差得实在有点远,尤其那个扎起来的头发完全不科学,一个人的发量是有限的……另外就是SD图的眼睛的侧面感觉不正常,下睫毛即使从侧面看也不会是这种效果。哦还有,SD生成的那个锅把手也不对……
3. 建筑/物品/动物

提示词:low angle close-up photo of the Eiffel Tower, on a sunny day in Paris, center composition
SD3.5 be like:别打了求求你了这个伦家真的打不过嘤嘤嘤(☍﹏⁰)。

SD3.5扳回一城!虽然质量上感觉差的不多,但是Flux的景深未免太离谱了,而且Flux也没有做出来silver sparkles而是做成了golden sparkles(不过Flux理解了“只伸出一只爪子”)。SD3.5的猫爪质量比较捉鸡,但是Flux显然对seal bicolor ragdoll cat是啥一无所知(这也是为啥我后来自己训练了一个LoRA……),SD3.5的虽然也不是我要的那个猫,但它至少看着也像是一个point ragdoll……

不得不承认SD3.5的aesthetic真是……on another level。虽然它没有完全遵循我提示词里最后说的“pink and purple corals decorating the bottom of ocean wave fondant”(珊瑚不在底边在上面),也没有做出来我说的“forming a curved shape like a blooming rosebud”,但是我真的非常喜欢SD的配色(尤其是这个蓝绿色的渐变,太好看了),以及整体的美学呈现。Flux虽然正确遵循了我的“rosebud”提示词,但也没有get到底边的装饰应该是珊瑚形状的而不是玫瑰,而且它外层的那个浪花看着就很low,离SD3.5的审美差很远。(SD生成的那个蛋糕底座的紫色丝带倒是……有点破坏氛围,但是这种东西也容易P掉)
各类美术风格
1. 漫画/动画/简笔涂鸦等

这轮两个都输得够惨的……首先两个模型都不晓得“1980s Retro manga”是指的啥,SD的看起来就是比较generic的现代插画,FLUX的好像也……反正都离我们普遍认知离的80年代漫画差很远。FLUX对于“a long clothing made of white waterlily flowers and green leaves”的理解还是要比SD强很多(不过这点我也早就知道了……),以及FLUX也做出了我想要的背景,大概是因为训练素材完全不一样,我感觉这两个很难对比……

这轮SD被捶得死死的。首先这个猫就没坐在电脑椅上,爪子也没放在键盘上,画风也不是我想要的那种简洁的矢量图风格,相比之下FLUX除了把猫生成对眼儿了以外基本上没毛病。

SD又扳回一城!首先我要的就是Crayon drawing(蜡笔画),所以很明显我想要的就是一种比较随意、比较粗糙的感觉,不应该有像FLUX出的图这种过于精致过于严格的线条。SD的图虽然也不完全像蜡笔(感觉更像细的彩笔一点),但是很有我想要的那种粗糙的普通人手绘的感觉,加分!
2. 其他美术风格

这个怎么说呢……虽然我更喜欢FLUX的配色,但是SD的出图应该更符合人们印象中的“retro pixel game art”,像素块要大一些,而且色彩非常鲜艳以及高对比(笑死,看多了晃眼睛),两个模型生成这段文字都非常轻松。那我就暂且说它们打了个平手吧!

呃……虽说确实都是3D动画风格吧,但是!!!但是SD这个未免也太丑了!我喜欢SD的那个翅膀,但是脸真的好难看……FLUX感觉相对来讲更接近马达加斯加的企鹅那种风格。虽然FLUX图里拿着牌子的翅膀连接到身体的部分好怪啊……就好像只有细细的骨头……SD的版本,拿着牌子的部分也好怪,怎么有手指XD

SD拿下最后一轮!我感觉FLUX在鱼的那半部分其实还不错,看起来确实是油画的感觉,但是猫的部分就实在太假了,而且鼻子嘴那块好像也怪怪的,眼睛好像也太大了……SD的版本就很符合我预期的样子,虽然后腿的位置有点崩了,但是我还真的蛮喜欢SD的配色(FLUX甚至没听我话做“the water is dark blue colored”)。
转自:秘问
来源链接:https://mp.weixin.qq.com/s/8WRupgG__z7m2SI_lxFnMA
© 版权声明
文章版权归作者所有,未经允许请勿转载。