开源周序幕:FlashMLA 引爆 AI 社区
上周我们介绍了 DeepSeek 提前预告本周要连发 5 个开源项目。
2 月 24 日 9:34,DeepSeek 正式拉开“开源周”序幕。
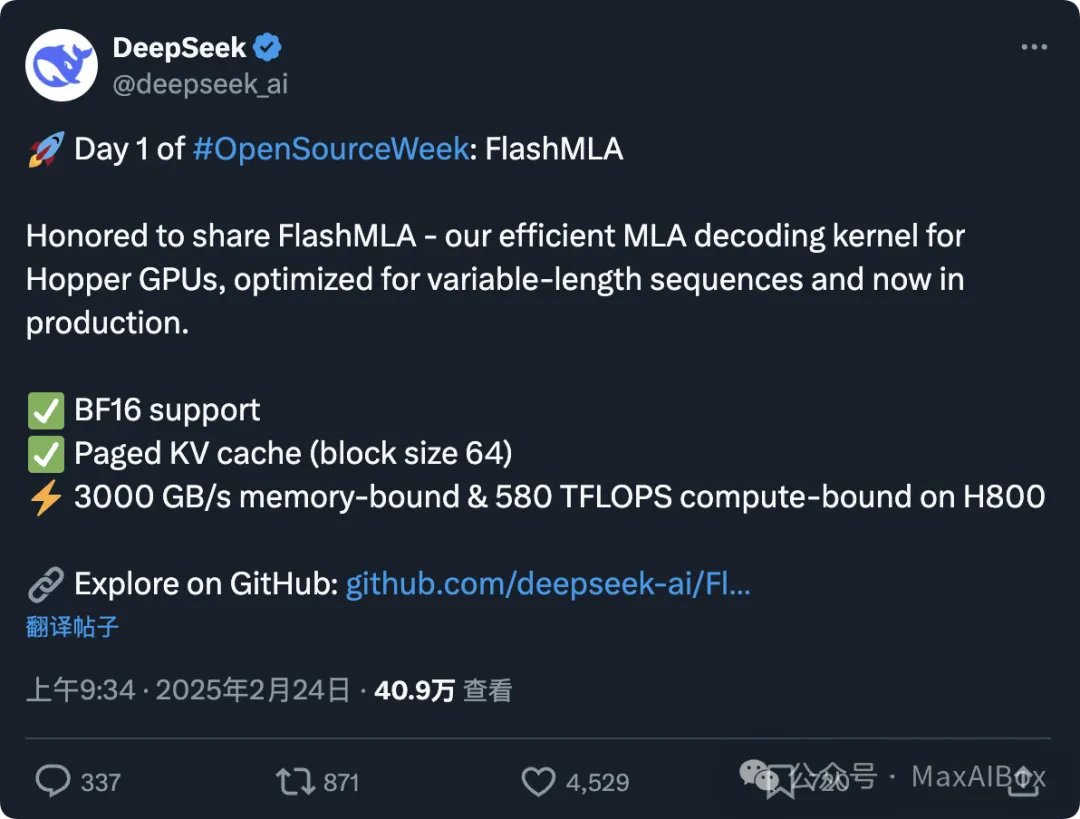
首个开源项目 FlashMLA,专为英伟达 Hopper 架构 GPU 优化的高效 MLA 解码内核,上线仅 4 小时在 GitHub 斩获超 3800+ Star,成为全球开发者社区热议的焦点。
https://github.com/deepseek-ai/FlashMLA
这一技术不仅将 H800 GPU 的性能推至 3000GB/s 内存带宽与 580 TFLOPS 算力的新高度,更以开源姿态重塑大模型推理加速的竞争格局。
技术解析:FlashMLA 的三大核心突破
1、 分页 KV 缓存:显存管理的革命
FlashMLA 引入块大小为 64 的分页式 KV 缓存,通过动态内存分配策略,将传统连续显存管理的碎片率降低 70%,显存利用率提升 30%+。这一设计尤其适用于对话式 AI 中长短请求混合的场景,支持单卡并行处理超 200 个对话线程。
2、 BF16 精度与 Hopper 架构深度适配
通过支持 BF16 浮点格式,FlashMLA 在保持模型精度的同时,将推理显存占用降低 50%,并利用 H800 的 Tensor Core 特性实现混合精度计算加速。实测显示,千亿模型端到端推理延迟降低 40%。
3、 变长序列优化:破解行业痛点
针对自然语言处理中输入长度不定的难题,FlashMLA 采用动态计算图拆分策略,减少填充(padding)导致的资源浪费。在长文本处理场景(如 10 万 token 金融文档分析),吞吐量提升 2.3 倍。
Quick Start
1、 安装
python setup.py install
2、 基准测试
python tests/test_flash_mla.py
3、用例
from flash_mla import get_mla_metadata, flash_mla_with_kvcache tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv) for i in range(num_layers): ... o_i, lse_i = flash_mla_with_kvcache( q_i, kvcache_i, block_table, cache_seqlens, dv, tile_scheduler_metadata, num_splits, causal=True, ) ...
4、要求
- Hopper GPUs
- CUDA 12.3 and above
- PyTorch 2.0 and above
未来展望:开源生态的链式反应
DeepSeek 预告后续 4 天将开源更多工具库,社区猜测可能涉及分布式训练框架或多模态对齐技术。
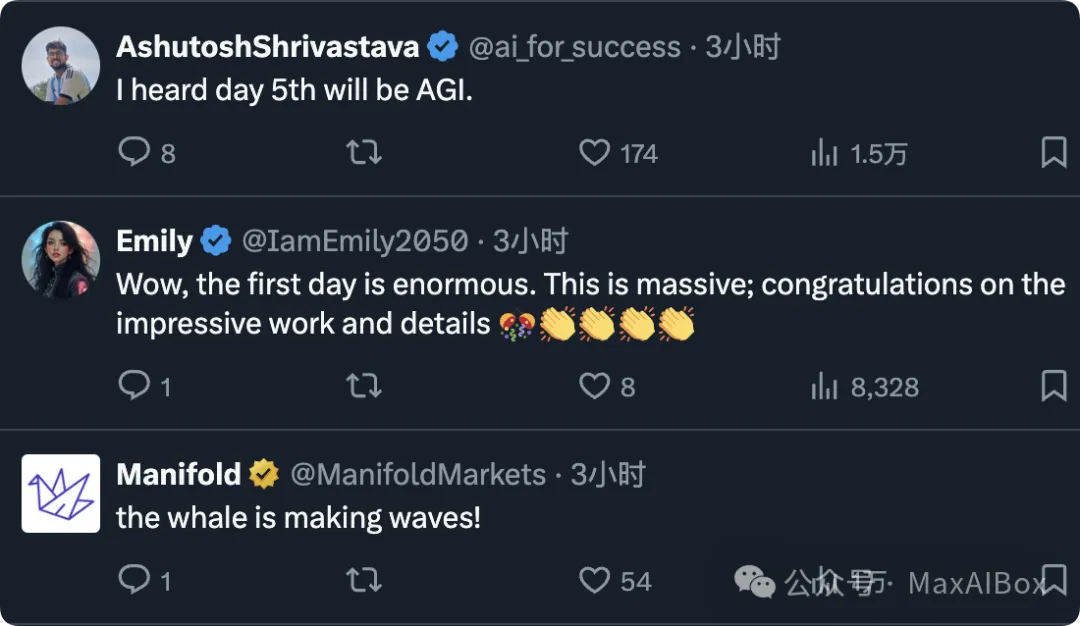
外网网友称 “(DeepSeek)这条蓝鲸鱼正掀起波浪咯!”,甚至还有人戏称:“第五天会不会直接开源 AGI?” ,
© 版权声明
文章版权归作者所有,未经允许请勿转载。