AI 算力竞争愈发白热化的 2025 年,英伟达在 2 月 25 日投下一枚技术核弹:基于 Blackwell 架构的 DeepSeek-R1-FP4 模型横空出世。
这项突破不仅让推理速度暴增 25 倍,更将成本压缩至传统方案的 1/20,彻底改写了 AI 部署的经济学规则。

传送门:https://huggingface.co/nvidia/DeepSeek-R1-FP4
FP4 + Blackwell:一场精度的艺术
传统 AI 模型普遍采用 FP16 或 FP8 精度,而 DeepSeek-R1-FP4 首次将权重和激活值量化至 FP4(4 位浮点)。
通过英伟达 TensorRT-LLM 的优化,模型在 MMLU 基准测试中实现了 FP8 模型 99.8%的性能,却仅需 1/2 的显存和磁盘空间。
这种“用 4 位精度跑出 8 位效果”的黑科技,本质是通过动态量化策略,在计算关键路径保留高精度,而在非敏感区域极致压缩。
B200 碾压 H100:25 倍吞吐量神话
搭载 Blackwell 架构的 B200 GPU,配合 FP4 量化方案,交出了 21,088 token/秒的恐怖成绩单。对比前代 H100 的 844 token/秒,推理速度提升达 25 倍。
更惊人的是,每 token 成本骤降 20 倍,使得企业部署百亿级大模型的边际成本趋近于零。有开发者测算,基于该技术构建的 API 服务,每百万 token 成本可低至 0.25 美元且仍有利润空间。
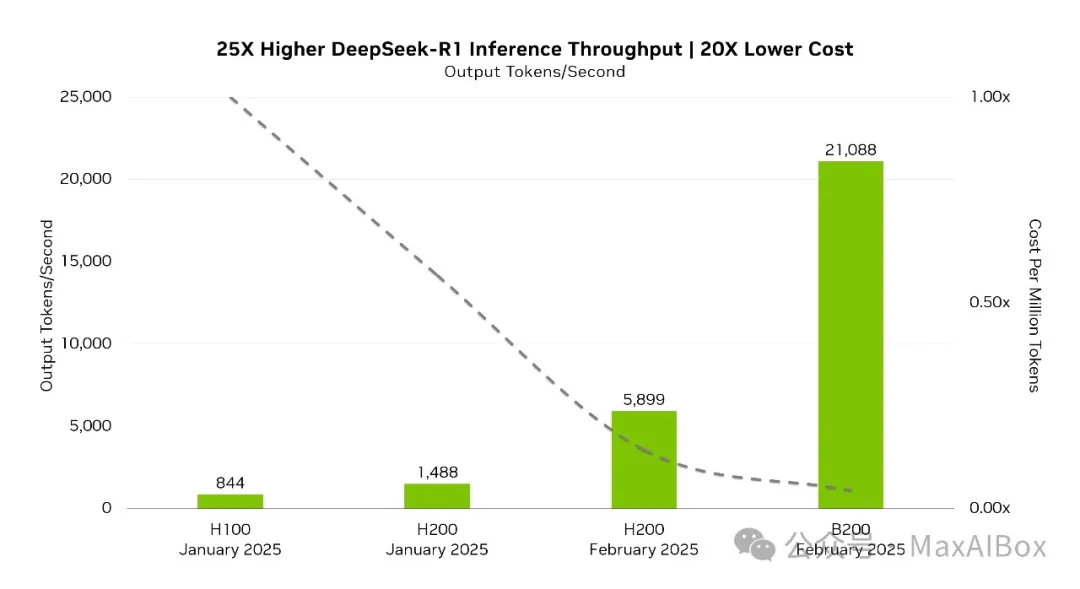
上面这张图表,对比了不同 GPU 型号(H100、H200、B200)在输出令牌速率和每百万令牌成本上的表现:
纵轴:输出令牌速率(Output Tokens):
- B200(2025 年 2 月)输出速率达 25,000 tokens,是 H100(1,000 tokens)的 25 倍,H200(5,899 tokens)的 4.2 倍。
时间线显示硬件迭代速度极快:H200 在 2025 年 1 月至 2 月性能提升约3.5 倍,而 B200 在同期直接碾压前代。
未来之战:4 位精度的边界探索
尽管 FP4 已展现惊人潜力,业界仍在探索更低精度(如 FP2)的可能性。
英伟达工程师透露,Blackwell 架构的动态精度切换技术已进入测试阶段,未来可能实现“关键计算用 FP4,普通计算用 FP2”的混合精度模式。这场比特级的战争,正在重新定义 AI 的算力经济学。
网友评论
“DeepSeek-R1 在 Blackwell 上的优化简直太疯狂了。25 倍的收入增长和 20 倍的成本降低,这种进展简直不可思议。我特别喜欢它与 DeepSeek 本周开源推动的结合,展示了硬件与开源模型结合后所能实现的巨大潜力。”
DeepSeek 开源周到 26 日已经连发三弹了:
© 版权声明
文章版权归作者所有,未经允许请勿转载。