DeepSeek 开源周第三弹:DeepGEMM
2 月 26 日是 DeepSeek “开源周”的第三天,今天 DeepSeek 隆重推出 DeepGEMM:一个支持稠密和 MoE(专家混合)GEMM 运算的 FP8 矩阵乘法库,为 V3/R1 的训练和推理提供强大动力。
DeepGEMM 的亮点:
- ⚡ 在 Hopper GPU 上实现高达 1350+ FP8 TFLOPS
- ✅ 无重度依赖,简洁如教程
- ✅ 完全即时编译(JIT)
- ✅ 核心逻辑仅约 300 行代码 —— 却在大多数矩阵尺寸上超越专家调校的内核
- ✅ 支持稠密布局和两种 MoE 布局

DeepGEMM 是什么?
DeepGEMM 是一个专为简洁高效的 FP8 通用矩阵乘法(GEMM)设计的库,具有细粒度的缩放功能,正如 DeepSeek-V3 所提出的。它支持常规的以及专家混合(MoE)分组的 GEMM 运算。该库使用 CUDA 编写,安装时无需编译,通过一个轻量级的即时编译(JIT)模块在运行时编译所有内核。
目前,DeepGEMM 专门支持 NVIDIA Hopper 张量核心。为了解决 FP8 张量核心累积不精确的问题,它采用了 CUDA 核心的两级累积(提升)方法。尽管它借鉴了 CUTLASS 和 CuTe 的一些概念,但避免了对它们模板或代数的重度依赖。相反,该库的设计追求简洁,仅包含一个核心内核函数,代码量约为 300 行。这使其成为学习 Hopper FP8 矩阵乘法及优化技术的清晰且易于理解的资源。
尽管 DeepGEMM 设计轻量,但其性能在各种矩阵形状上均匹配或超越了专家调校的库。
DeepGEMM 性能如何?
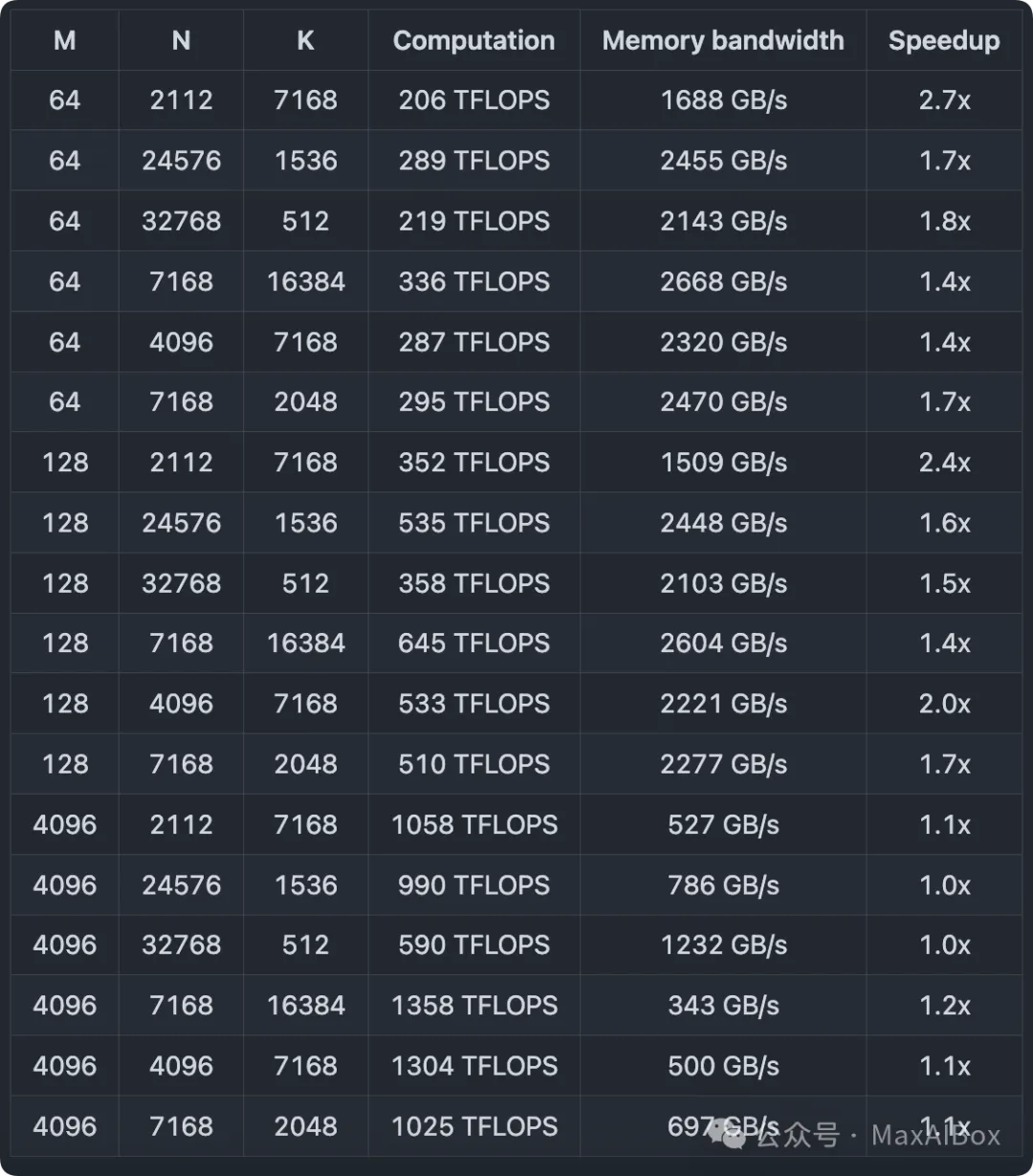
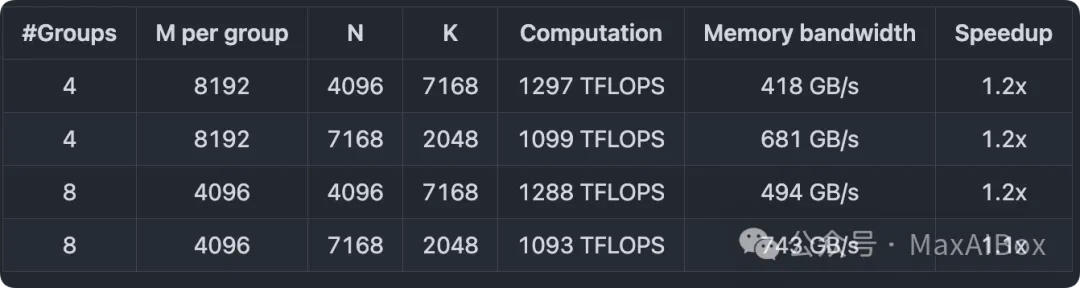
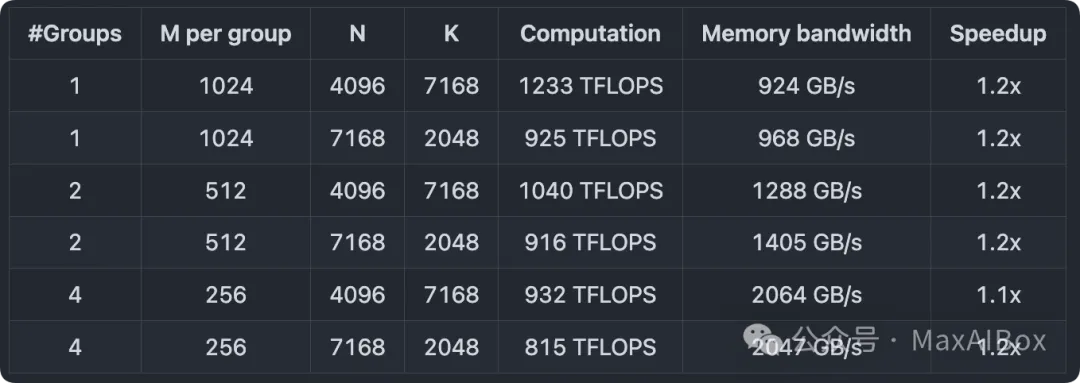
DeepSeek 在 H800 GPU 上使用 NVCC 12.8 测试了 DeepSeek-V3/R1 推理中可能使用的所有形状(包括预填充和解码阶段,但不包括张量并行)。所有加速指标均基于 DS 内部精心优化的 CUTLASS 3.6 实现进行对比计算。
DeepSeek 官方表示,DeepGEMM 在某些形状上表现并不十分理想,感兴趣的盆友可以去提交优化 PR(Pull Request)。
传送门:https://github.com/deepseek-ai/DeepGEMM
稠密模型的常规 GEMM
MoE 模型的连续布局分组 GEMM
MoE 模型的掩码布局分组 GEMM
社区反馈 + 网友评论
有网友称,
DeepGEMM 听起来确实像数学界的超级英雄!比飞速的计算器还快,比多项式方程还强大。我试着用了它,结果我的 GPU 现在炫耀着它的 1350+ TFLOPS,仿佛已经准备好参加 AI 奥运会了!🥇
是不是看不懂 DeepGEMM?听听网友的解释:
兄弟们,这是@deepseek_ai 的一项巨大成就!🚀 他们的 DeepGEMM 库真的要在 AI 世界里改变游戏规则了。
让我简单解释一下:
- FP8 GEMM:让复杂的计算更快、更轻量,节省时间和能源。
- MoE 布局:模型专注于“迷你专家”来解决问题,就像我们每天使用不同的技能一样。
为什么这很重要?
- 疯狂的速度:每秒超过 1,350 万亿次运算!🚀
- 易于使用:核心代码仅 300 行,但性能惊人。
- 没有复杂性:轻量级且快速加载。
想象一下:如果训练 AI 是做饭,这个库让你能在几分钟内搞定复杂的菜肴!🍳
截至 MaxAIBox 18 点发稿为止,DeepGEMM 在 GitHub 获得 2900+ Star,在推特被👍 4400+。
- 24 日开源的 FlashMLA 接近 10,000 Star
- 25 日开源的 DeepEP 为 5770 Star
DeepSeek 开源周系列:
© 版权声明
文章版权归作者所有,未经允许请勿转载。