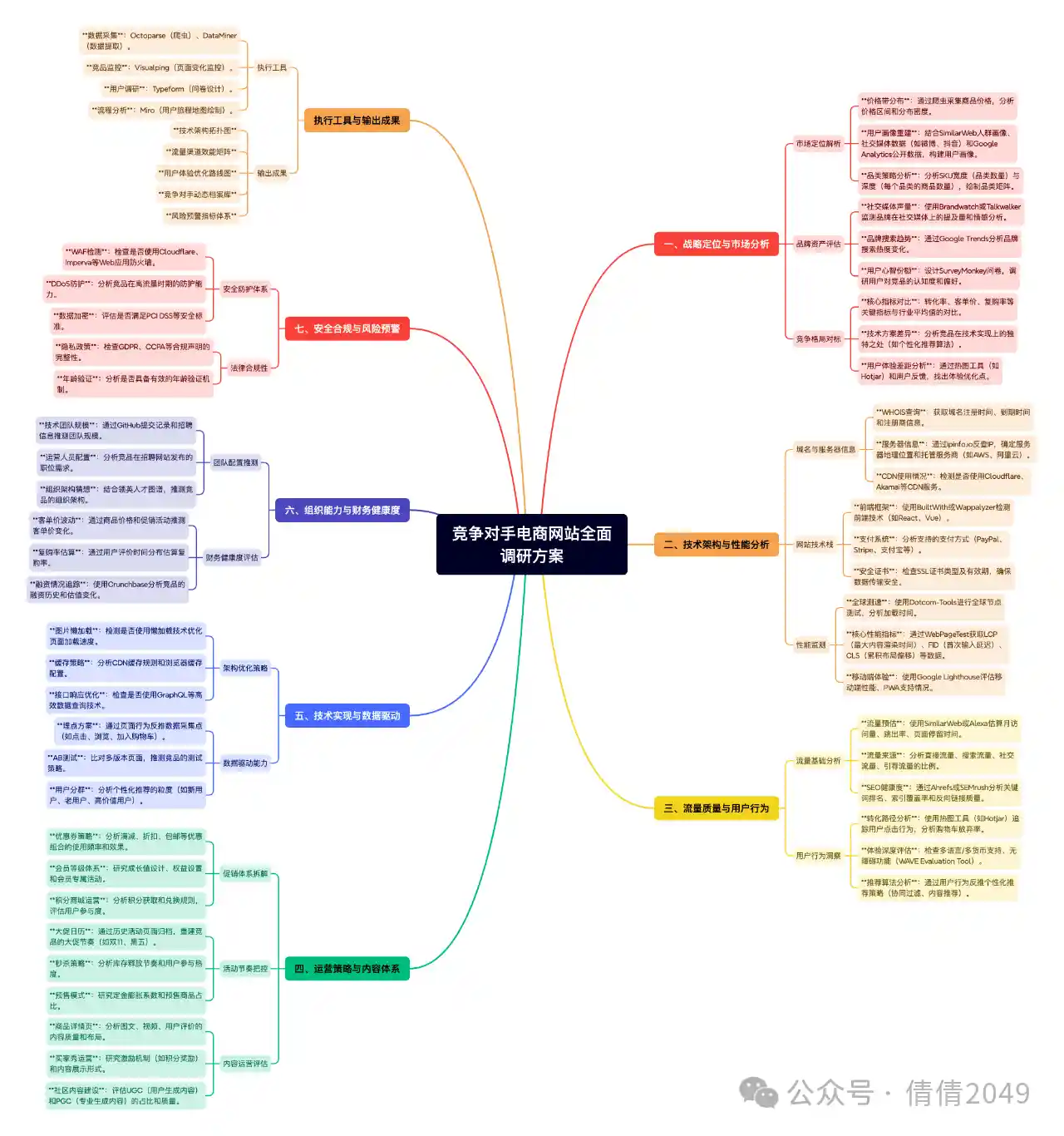
DeepSeek 开源周第四天
2 月 27 日是 DeepSeek “开源周”的第 4 天,今天 DS 一下就 Open 了三个仓库:DualPipe、EPLB 和 Profiling Data。
- DualPipe 从时间上优化了计算与通信的调度,
- EPLB 从空间上平衡利用计算资源,
- Profiling Data 则提供了前两者在实际应用中效果的可视化证据

并且在 DualPipe 的开发者中,就有梁文峰本人。(一点也不意外。jpg)

DS 开源周系列:
今日亮点
训练速度更快:DualPipe 通过将计算和通信重叠,消除了空闲时间,就像接力赛中接力棒从未停止移动一样。以往拖沓的训练现在能更快完成。
成本节约:通过更充分地利用每块 GPU,DeepSeek AI 声称与竞争对手相比,他们已将计算需求削减了高达 11 倍,仅使用 2,048 块 Nvidia H800 GPU,而无需更昂贵的配置。更少的硬件,更低的账单。
可扩展性:这些技巧让你能够扩展模型(比如 DeepSeek V3 的 671B 参数),而无需额外的时间或资源。更大的模型,同样的舞台。
资源效率:EPLB 平衡了工作负载,确保没有 GPU 闲置,而 DualPipe 则让它们持续高效运转。计算和通信几乎完全重叠,最大化硬件利用率。
与大玩家的对比
DeepSeek AI 的方法与 OpenAI、Google 和 Meta 等巨头竞争,但有一个不同点:效率。虽然其他公司可能会用 Nvidia H100 组成的大规模集群来炫耀,但 DeepSeek 通过“减配版”H800 和巧妙的优化实现了有竞争力的模型。
DualPipe 和 EPLB 让他们能够以更少的计算资源实现训练突破,凸显了创新如何超越原始算力。
如何形象理解 DualPipe 和 EPLB
技术文是不是不好理解?
要理解 DualPipe 和 EPLB,可以将其类比为指挥交响乐团:
每个 GPU 如同一位乐手,执行各自的计算任务,而训练框架则是指挥家,确保全局协调。在传统训练中,乐手需互相等待,产生无效的“停顿”(即流水线气泡),导致效率低下。
DualPipe:消除“停顿”的双向协作
技术原理:通过双向流水线并行算法,让前向计算(如弦乐部演奏)与反向计算(如铜管部排练)完全重叠,消除 GPU 等待时间。例如,切分训练块为注意力、全连接层等组件,并通过 GPU 流处理器(SM)的精细调度实现计算与通信的齿轮式咬合。
效果:
- 将训练效率提升最高达 11 倍(对比传统方法);
- 在 2048 块 H800 GPU 上即可实现其他方案需要更昂贵硬件的性能。

EPLB:专家模型的“动态调度舞台监督”
技术原理:针对混合专家模型(MoE),通过冗余专家策略复制高负载专家,并结合分层负载均衡(预填充阶段)和全局负载均衡(解码阶段),动态分配任务到不同 GPU,避免“乐手过劳”。
示例:若某个专家模块负载过高,EPLB 会将其复制到多个 GPU 并行处理,同时优化跨节点通信。
效果:
- 确保所有 GPU 满负荷运转,闲置率趋近于零;
- 减少跨节点通信开销,提升资源利用率。

协同价值:从“混乱排练”到“完美演出”
DualPipe 与 EPLB 的结合,如同为乐团引入智能调度系统:
1、 DualPipe 优化时序:通过计算-通信重叠,让 GPU 像乐手同时演奏不同乐章,消除传统流水线的“气泡”等待。
2、 EPLB 平衡资源:动态分配专家任务,防止部分 GPU 过载或闲置,如同指挥家根据乐手状态实时调整声部强度。
3、 成本与效率双赢:相比依赖硬件堆叠的方案,算法优化可减少 50% 以上的算力成本,同时加速模型迭代。
传送门:
https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
https://github.com/deepseek-ai/profile-data
© 版权声明
文章版权归作者所有,未经允许请勿转载。